
TL;DR
All the code examples from this articles you can find on a GitHub repository https://github.com/AndrejsAbrickis/axios-cheerio-puppeteer
. . .
Axios and cheerio is a great toolset to fetch and scrape the content of a static web page. But nowadays when many of the websites are built as a single page application and gets rendered dynamically on the client it might not be possible to get the content.
Just because it’s rendered asynchronously and the content is not backed into the HTML received over the wire, doesn’t mean you cannot access it. You just need a different toolset which allows waiting for the content to appear.
Let’s have a quick look on the source HTML of a SPA application and the rendered result.
](https://cdn-images-1.medium.com/max/5584/1*rf9VXhBcni3ub-I_UHO9Ug.png)
In the screenshot above, on the left, you can see a fully rendered
standings table. But look at the source the browser downloaded all we
can notice is a single
<div id="#app"></div> and a couple of
JavaScript files and NO content. So let’s try to get the HTML content of
the body.
Start with axios + cheerio
axios is a “Promise based HTTP client for the browser and node.js”. Because it’s an HTTP client we can use it to fetch an HTTP endpoint and receive the response with the body. We can use the HTTP client to fetch not only HTML endpoint but also JSON, images, etc. And hence we are responsible to handle the plain text response.
That’s where the cheerio comes to help. Cheerio is a “Fast, flexible & lean implementation of core jQuery designed specifically for the server”. Basically, it loads and parses the HTML markup as plain text and returns a DOM model we can then access and traverse in jQuery style.
And because cheerio doesn’t interpret the markup as a browser does. It won’t apply the CSS styles and won’t run the JavaScript and the dynamically rendered content won’t be added to the DOM.
As an example let’s try to get the content of the body tag using axios
and cheerio. In the following gist you can see that we are firing a GET
request (L6), then parse the response data into a DOM using cheerio (L7)
and finally search for the <body> element (L9) to
output its HTML content.
const axios = require('axios');
const cheerio = require('cheerio');
(async () => {
try {
const response = await axios.get('https://bvopen.abrickis.me/#/standings');
const $ = cheerio.load(response.data);
console.log($('body').html());
} catch (error) {
console.log(error);
}
})();
When executed this node script we get the web apps placeholder element
<div id="app"> without the dynamically rendered
content.
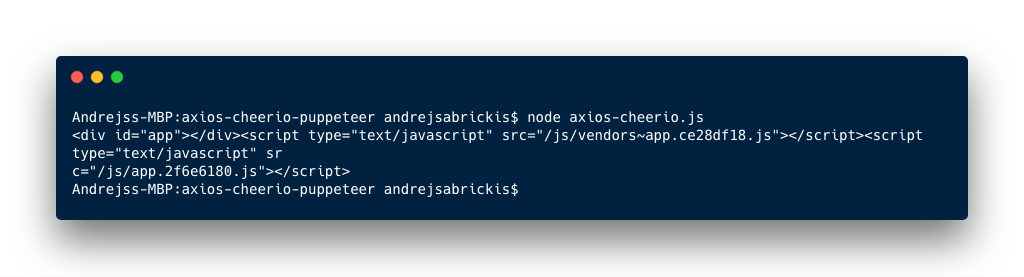
Because of what we received over the wire was a plain text and the JavaScripts included in the HTML were not executed and this is where a headless browser comes to rescue.
Switch to puppeteer and headless Chrome
Let me shortly explain what a headless browser is. In a nutshell headless means it’s a browser without graphical user interface (GUI) which can be controlled programmatically. Mostly it’s useful for E2E testing as it will apply all styles, and run JavaScript to generate the DOM. And because of that, it’s a perfect tool to scrape Single Page Applications.
And as I mentioned that it’s controlled programmatically. And for that reason, we can use puppeteer to control the browser over the DevTools protocol. Let’s get hands-on and see how to get the dynamically rendered HTML.
const puppeteer = require('puppeteer');
(async () => {
try {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://bvopen.abrickis.me/#/standings');
await page.waitForSelector('.category', { timeout: 1000 });
const body = await page.evaluate(() => {
return document.querySelector('body').innerHTML;
});
console.log(body);
await browser.close();
} catch (error) {
console.log(error);
}
})();
In the example above we are using single dependancy pf puppeteer package. First, we initialize a browser instance (L5) and create a new browser page (L6). Afterward, we instruct the browser page to visit an URL (L7) and wait for an element to appear on the page (L8) before to continue. Notice that one can set the timeout in milliseconds how long the browser should wait for the element.
After we have awaited the element we are using page’s evaluate method to execute a JavaScript within the web page’s context (L10 — L12). This allows us to access the HTML document using vanilla DOM API. From this, we return the HTML of body element and output. And finally, we close the browser which kills the headless Chrome’s process.
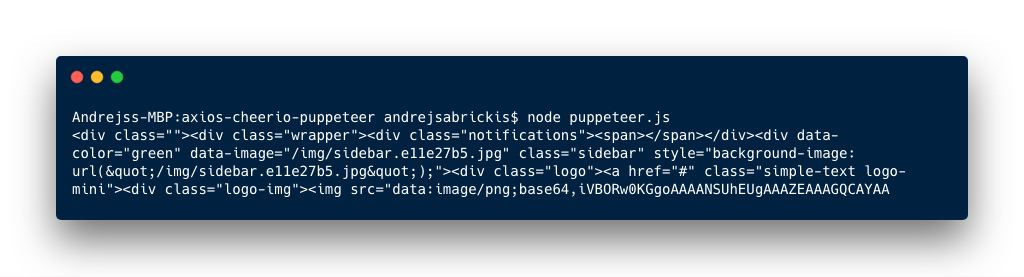
And now the result of running this script includes the content of dynamically rendered HTML.
Conclusion
This short post demonstrated two solutions how to scrape a website. One can use a combination of axios and cheerio to get the content of a statically rendered website. And use puppeteer to get a dynamical content which is rendered by a fully-powered and invisible (headless) browser.
I hope this article will help you to start to utilize the mentioned tools as they can be used not only to scrape the websites but also for testing your web apps (E2E or snapshot tests) or taking screenshots.
. . .
If you found this post useful and would like to read more about random web development topics, just clap for this article or drop a comment here. And as always you can find me on Twitter@andrejsabrickis
. . .
This article, the content, and opinions expressed on Medium are my own. But as I work for one of the leading P2P loans marketplaces Mintos.com I would like to use this last line to promote that we are hiring. Including the Growth Engineering team, I am leading at the moment.
You can see all list of the open positions on our Workable board. And feel free to contact me directly if you find something interesting in the list or would like to recommend a person you know.
Cheers!